Accessed times
摘要:
隨著網際網路的蓬勃發展,各地圖書館也在加緊自動化與網路化的腳步。其中,跟讀者最直接相關的為「線上公用目錄」服務。本文提出建置在
WWW 的分散式 OPAC 系統架構,其優點有:一、介面一致、簡單易用;二、充分運用使用者端的電腦資源;三、無使用者上線人數的限制、並且只需極少的使用者授權人數;四、開發簡易、不與既有系統衝突;五、超連結、分散式處理、降低對大型主機的依賴;六、多媒體、擴充能力佳;七、易與其他資訊系統結合。文中並以輔仁大學最近建置的
OPAC系統為例,介紹此種架構的實施過程。我們分別以
Windows NT 與 Linux 作業系統架設了兩部主機。其中
Linux 主機安裝中研院資科所發展的
Csmart 系統,讓使用者可以用近似自然語言的方式下達查詢條件。而
Windows NT 主機則用以查詢詳細的書目資料。我們發現,新的網路與分散式處理技術,可以讓我們運用較為普及、甚至免費的軟硬體,以較低的成本、較高的時效,建構出功能更為強大的系統。
Abstract:
This
paper proposes a distributed on-line public access catalog (OPAC)
system based on WWW technology. The advantages of such system
are: user friendly, better utilization of client-side computers,
virtually no limitation on number of on-lined users, very few
user licence required, fast deployment, distributed processing,
enhencable and expandable, and ease of integration with other
information systems. The development of the OPAC system of FU
JEN Catholic University is introduced as an example, where two
servers have been setting up, one for detailed bibliographic search,
and one for query by quasi-natural language, a technology developed
by Institute of Information Science, Academia Sinica . We conclude
that with current network and distributed processing technologies,
we are able to develop a powerful OPAC system by use of more prevailing
hardware and even free software in less time and cost.
關鍵字:全球資訊網,分散式處理,線上公用目錄系統,自然語言檢索
網際網路發展之初提供的服務主要有遠程登錄 (telnet)、電子郵件(email )、檔案傳輸 (ftp),其使用者層面較窄,以美國軍方及具備較高專業知識的大學學生為主。雖然 email 具有商業應用的價值,但其時網路的建置還相當昂貴,網際網路還未普及到民間與一般的商業公司。
近年來硬體與軟體的日益進展,使個人電腦的計算與通訊能力越來越強,再加上大量的免費使用或試用軟體,以及網路上越來越多的資訊系統,如 News、Gopher、BBS、WWW (World Wide Web)等,使得網際網路的普及到了水到渠成的地步。國內目前約有五十萬人的使用者,隨者政府的重視與民間的投資,未來三年將推廣至三百萬的使用人口。
在這一波網路服務的建設中,各地圖書館也在加緊自動化與網路化的腳步。其中,跟讀者最直接相關的為「線上公用目錄」(OPAC,
On-line Public Access Catalog)服務。由於
WWW 具有超連結、多媒體的特性,近來各個圖書館自動化的廠商遂相繼發展以
WWW 為介面的OPAC 系統。本文介紹傳統查詢介面的缺點,剖析以
WWW 為使用者介面的優點,並以輔仁大學最近建置的
OPAC系統為例,介紹此種架構的實施過程。我們分別以
Windows NT 與 Linux 作業系統架設了兩部主機。其中Windows
NT 主機以傳統的資料庫軟體系統提供的功能查詢書目資料,並顯示每一筆記錄的詳細書目。而
Linux 主機安裝中央研究院資訊科學研究所發展的
Csmart 系統,讓使用者可以用近似自然語言的方式下達查詢條件。例如,讀者可以輸入「基本心理學導論概論原理入門」、「德川加康」、「胡適寫的文存」等內有同類字、錯字或冗字的字串,只要字詞間透露讀者想找的書目名稱即可。我們發現,新的網路與分散式處理技術,可以讓我們運用較為普及、甚至免費的軟硬體,以較低的成本、較高的時效,建構出功能更為強大的系統。
在 WWW 還未出現以前,圖書館的線上公用目錄主要以遠端登錄 (telnet)的方式,提供網路使用者時、空無礙的查詢檢索。Telnet 的優點在於整個查詢的過程中系統一直維持與使用者的連線、並維護使用者查詢的狀態,使得查詢結果的修飾,如縮小範圍、不同查詢結果的聯集運算等,可以直覺的進行。然而 WWW 出現後,卻相對的暴露出以 telnet 為使用者介面的許多缺點。茲列舉如下:
一、只有文字模式,缺乏展現多媒體的能力。而且受限於文字模式顯現字數的限制,顯現的資料常有截斷或濃縮的現象。
二、以終端機模擬方式提供使用介面,游標的移動、文字的輸入、畫面的轉換,均需傳送回遠方主機才能更新畫面,在網路擁塞時,系統回應速度緩慢,並且不能利用已經傳送過的資料加快畫面的顯示。此外,查得的資料需逐頁的顯示,不利於大幅度的翻頁檢視。
三、不同的系統,採用不同的指令與操作方式,對使用者造成困擾。
四、使用者上線人數受限,擴充使用者人數(user licence)的權利金高昂。一般 Unix 主機,同一時段中接受 telnet 方式簽入(login)系統的人數有限,此人數上限與 CPU 速度、主記憶體容量及使用的軟體有關。Telnet 簽入乃專線獨佔,具有排他性,即簽入一名,後續連線的人數便減少一名。若使用者簽入後不做任何事或不熟悉系統的操作而流連徘徊於各項功能說明之間,將造成系統使用效率的低落。
五、查詢檢索程式在
telnet 的架構下,不具備跨平台的特性,軟體移植性差。目前只有
Unix 等大型系統提供
telnet 連線方式,Windows
NT 等系統還未提供,使得軟、硬體的建置費用與維護成本高昂,無法利用較為普及與平價的硬體平台與軟體。
WWW 技術出現後,恰可改進上述缺點。WWW 作為使用者介面的優點有
一、介面一致、簡單易用
WWW 圖形化的介面、超連結的功能,使用者只需根據畫面上的圖示或簡短說明,利用滑鼠的點選操作即可,免除查閱並記憶指令的過程。目前網路技術的發展,有傾向於使用者只要學會瀏覽器的使用,即可享受各種網路服務的趨勢。
二、充分運用使用者端的電腦資源
使用者移動游標、輸入資料或畫面轉換時,只由使用者端的電腦處理,不必等待主機端的回應。而且大部份的瀏覽器會將傳送過的資料做備份,使再次抓取或顯示的速度加快,降低網路的負荷量。此外查詢的資料若經傳送完畢,使用者就可以快速翻閱檢視,不受網路速度的影響。若查得的資料數量很大時,逐筆的瀏覽檢視還是相當吃力。這種情況,可利用瀏覽器的字串搜尋功能,做快速跳躍,加快資料的瀏覽篩選。
三、無使用者上線人數的限制、並且只需極少的使用者授權人數
WWW 以 HTTP(HyperText Transfer Protocol)的通信協定連線,此協定的特點是每次傳送資料就要重新建立連線,資料傳送完畢後,就斷線。這使得使用者下完查詢條件,要求檢索資料時,才需要連上主機,伺服器端一旦查到資料並傳送完畢後,隨即斷線,等待下一位使用者的查詢。一般 WWW 伺服器可同時接受多個使用者的查詢,但畢竟人數還是有限,可是若查詢與傳回資料的速度夠快,很快就服務完一個查詢,對使用者而言則幾乎沒有上線人數的限制。網路上的 Alta Vista 檢索引擎一星期可服務兩千萬人次,即為例證 [1]。也由於此原因,甚至有商業公司建議使用客戶只需購買兩個使用者授權人數就夠了,一個作為查詢用,一個作為維護、發展系統用[2][3]。
四、開發簡易、不與既有系統衝突
以 telnet 為介面的查詢檢索程式在資料庫管理系統的支援下,查詢存取資料並不困難,反而要在文字模式下與使用者做友善、直覺的互動需花一番工夫處理。現在透過 WWW 的架構,使用者介面可以用 HTML(HyperText Markup Language) 語法完成,如有必要則輔以 Java或 ActiveX 程式的互動效果。而查詢程式則在伺服器端透過 CGI(Common Gateway Interface)介面及資料庫介面來處理資料庫的存取、查詢與輸出結果的版面安排。這種架構使得系統具備更高的模組化,變更模組或加強模組功能不會影響到其他部份。因此,如台大、清大等原來就有OPAC 系統(telnet 版本)的大學,很快就有了 WWW 介面的系統。
五、超連結、分散式處理、降低對大型主機的依賴
一般的查詢模式都以兩個階段來顯示資料,第一階段顯示每一筆記錄的簡略資料,待使用者選定某一筆記錄後,在第二階段再顯示該比記錄的詳細資料。此兩階段可視為二次的查詢,第一次查詢的範圍較廣,第二次則指定查出某筆記錄。透過 WWW 的超連結能力,此兩階段查詢可以分散在不同的主機處理,減輕查詢主機的負擔。甚至,第一階段的查詢可以在另一部主機利用較先進的演算法,提供使用者更簡易的介面,例如以近似自然語言的方式來表達查詢主題 [4]。資料放在不同主機需要特別注意資料一致性的問題。所幸作為第一階段查詢用的書目記錄,不牽涉到需要及時更新的資料,如讀者預約記錄,此簡略書目不需要以每分鐘或每小時的速率更新,每天或每週的某幾天更新即可。在此情況下要維護資料的一致性較無問題,僅需在使用量最低時,如深夜或清晨,以程式自動更新即可。
六、多媒體、擴充能力佳
WWW 的架構不僅可以讓 OPAC 或類似的系統用來查詢書目記錄,也可以查詢影像、錄音帶、錄影帶、書法或繪畫等資料,並能播放一小段。目前此種系統雖然不普及,但已有一些已在網路上可以看到 [5]。
七、易與其他資訊系統結合
目前 WWW 上的資訊服務系統越來越多,例如中國圖書館學會在網路上就有一個「分類編目討論區」
[6][7],提供各地館員有關圖書分類與編目的參考服務。像這樣的系統也可以用來作為對讀者的參考服務或常問問答集(FAQ,
Frequently Asked Questions)使用,提昇網路化服務的品質。而與此類系統相連,只要建立一個超連結即可。
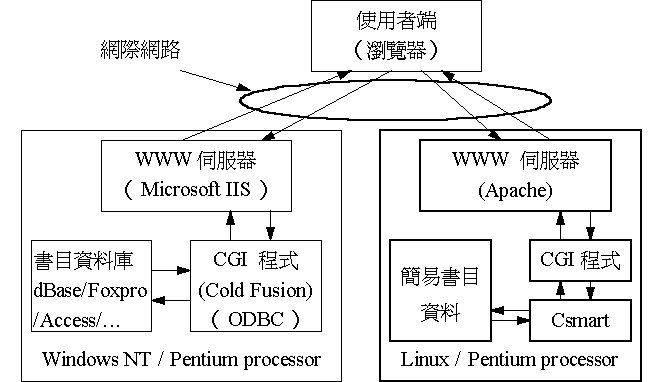
輔仁大學的 OPAC 架構如圖一所示,目前有兩套主機,都是以 Pentium 等級的個人電腦為硬體平台。一套主機安裝中文版 Windows NT 3.51 作業系統,存放完整的書目資料,並提供傳統的查詢檢索功能。底下我們先介紹這部主機內的架構,下一節再介紹其後才安裝的第二套系統。
在 Window
NT 裡我們採用為微軟公司的
IIS(Internet
Information Server)作為
WWW 伺服器,使伺服器與作業系統能緊密的結合,維持整體的效率。
WWW 伺服器與資料庫之間的介面程式則採用
Allaire 公司的
Cold Fusion 。Cold
Fusion 是先試用,後付費的軟體,可以在網路上取得
[8]。它能讓設計者以簡便、一致的方式存取資料庫的內容,並輸出成
HTML 檔案,而不必管資料是以何種格式儲存。其運作方式與
mSQL 的
w3-msql [9]
基本概念相同,不過它將「HTML中內嵌查詢語言」的概念進一步發展成「資料庫標示語言」(DBML,
DataBase Markup Language)的概念,使設計者只需撰寫
HTML 與
DBML程式即可完成
WWW 上的資料庫應用系統。Cold
Fusion 能抓取
WWW 伺服器送來的查詢資料,並允許設計者用SQL查詢語法(Structured
Query Language)表達查詢條件,透過資料庫軟體所附的
ODBC (Open
DataBase Connectivity)介面,可以存取、查詢
dBase、Foxpro、Access、MS
SQL 等多種資料庫的資料。查詢結果,則以
DBML 與
HTML來安排版面。Cold
Fusion 此種彈性的架構,使得我們將原先
dBase 格式的資料庫檔案,轉成
Foxpro 及
MS SQL 的資料庫檔案時,只需選用對應的
ODBC 介面,而完全不必更動到系統的其餘部份。
此系統的使用者查詢介面可以連到
http://140.136.250.38/cindex.htm
上看到。表一是使用者查詢畫面的 HTML 檔案。注意其中的一行:
Action="http://140.136.250.38/scripts/LIB.EXE?template=/CINDEX.DBM"
其中「LIB.EXE」是 Cold Fusion 的主程式,「template=/CINDEX.DBM」是其參數,指示 Cold Fusion 以 CINDEX.DBM 為模版,來處理此查詢。簡略過的CINDEX.DBM 檔案列在表二。Cold Fusion 根據此 "程式",從簡略的書目資料庫 "Lindex" 中查出符合條件的記錄,存放於變數 "L" 下,接下來則輸出這些記錄的「筆數」、「作者」、「書名」、「出版年」、「索書號」、「館藏」等資料。此乃第一階段的查詢。至於第二階段的查詢,使用者只要在「筆數」上用滑鼠點一下,即可查到該比記錄的詳細書目資料。這是透過下面這行敘述做到的:
<A HREF="/SCRIPTS/LIB.EXE?TEMPLATE=/DETAIL.DBM&BAR=#BAR#&Loc=L">#COUNT_REC#</A>
同樣的,「LIB.EXE」是
Cold Fusion 的主程式,「template=/DETAIL.DBM&
BAR=#BAR#&Loc=L」是其參數,指示
Cold Fusion 以
DETAIL.DBM 為模版,帶入「BAR="條碼號碼"」以及「Loc=L」作為參數,來處理此查詢。DETAIL.DBM
的大致內容列在表三。Cold
Fusion 根據此
"程式",從詳細的書目資料庫
"Ldb" 中查出符合所給條碼的記錄,將結果存放於變數
"ONE" 下,接下來則輸出這筆記錄的詳細書目資料。
Windows NT 主機是以傳統的資料庫管理系統(DBMS, DataBase Managemnt System)提供查詢功能。目前使用者可以查詢的檢索欄位為「書名」、「作者」與「關鍵字」。透過 DBMS 的索引功能,將「書名」、「作者」建立索引後,可允許「後切截」字串的快速搜尋。例如,在作者欄輸入「司馬」字串,可查得「司馬光」、「司馬中原」等作者寫的書目資料。DBMS在建立索引時會以特殊的資料結構儲存索引檔,使檢索的速度大幅提高,所以我們以五十萬筆記錄對「書名」、「作者」欄位做查詢測試時,其反應速度尚可接受。但是這種索引檔結構不利於字串「前後切截」的「關鍵字」查詢方式。例如,想要以關鍵字「物理學」來查詢,則系統幾乎只能每筆記錄都比對過才能找出「基本物理學概論」這樣的書。如此的檢索速度就難以符合要求了。
解決這個問題的方法有數種。一是改用執行速度較快的硬體平台。Windows NT 不僅可安裝在 PC 上,也可安裝在較高階的機器上,如 Alpha, MIPS 機器或其他工作站平台。此種作法最簡單,因為不用更動任何軟體,但書目記錄累積越多,其檢索速度就越來越慢,硬體就要再更換。
另一種方法是逐字索引。試舉一例:假若有三筆書目記錄:「中國通史」、「中國現代史」、「史記」,我們可為其建立如下的「字串索引檔」:
當使用者輸入「中國史」後,根據此檔會找出「中」出現在(1,2)筆記錄、「國」出現在(1,2)筆記錄、「史」出現在(1,2,3)筆記錄,經由交集(AND)運算,可找出第一、二筆記錄符合使用者輸入的字串。此種方法可以利用到 DBMS 儲存與管理資料的能力,不必自行開發全部的技術,並且經由 DBMS 對此「字串索引檔」的索引處理,可以加快查詢的速度。一些圖書館自動化廠商,根據其查詢反應,可能採用類似的作法 [10]。此「字串索引檔」可建立在同一部主機上,也可以建立於另一部主機,以分散處理查詢及儲存額外檔案的負擔。
上述的方法在儲存空間的利用上,並不是很有效率。如果平均每筆書目記錄有 10 個字要索引,總共有十萬筆記錄,則此「字串索引檔」雖然只有兩個欄位,卻要儲存一百萬筆記錄。另一個問題是,即便儲存空間用其他技巧解決,其檢索能力仍有不足。例如,使用者要找有關心理學入門的書,僅輸入「心理學」可能會找出「幼兒心理學」、「犯罪心理學」等專門的書,而與「心理學導論」、「心理學概論」、「基礎心理學」等書混雜。亦即,單純的(And, OR)布林邏輯(Boolean Logic)運算,不能表現出檢索結果之間重要程度的差別 [11]。
現今的資訊檢索技術已往智慧型、自然語言檢索的方向發展。全球資訊網上的檢索引擎已有近似的系統出現(如 Lycos [12]),我們希望這些先進的技術,也能用在傳統的資訊檢索服務上。目前國內對先進的資訊檢索技術已有研究,如中正大學的 Gais 系統 [13],以及中央研究院資訊科學研究所的 Csmart 系統 [14]。這些研究已有成果發表在網路上,供社會各界免費使用於非營利之公眾服務。我們選用 Csmart 系統,因為它非常適合我們目前的中文書目記錄。
目前我們獲得的 Csmart 系統可在 Windows NT 或 Unix 上編譯執行。我們評估的結果,雖然兩種系統上都有免費的 WWW 伺服器軟體、免費的程式發展語言(如 Perl),但是 Linux(PC 上的 Unix)是免費的,Windows NT 卻不是。所以我們選擇建構在 Linux(Unix) 系統上。這使得我們初期的建置費用只需要硬體採購及軟體的開發與維護成本即可。未來若 PC 平台無法勝任越來越繁重的查詢檢索時,只要換用較高等級的主機(Windows NT 或 Unix 系統皆可),而無須重新置換任何軟體程式。我們在第一部主機選用 Windows NT 的主要原因,是此平台上有眾多較為平價的資料庫管理系統,而其功能已足夠目前我們所需。所以整個分散式系統雖然採用不同的軟體與硬體,但卻是開放式的架構、模組化的設計,使得各部份能夠輕易的異動升級,而不會牽一髮動全局。此外,這種架構也可讓我們以較低價或現有的軟硬體平台,試驗新的系統及各模組之間的整合程度。
Csmart 檢索引擎能夠提供近似自然語言的查詢功能,查詢的結果會依相關程度由大到小排列順序。例如,前述查詢有關心理學入門的書,可以輸入「基礎心理學導論概論原理入門」這樣的字串,那們「基礎心理學」(比對到五個字,而且為連續的詞)、「心理學導論」、「心理學概論」、「心理學原理」、「心理學入門」(比對到五個字)等書就會被列在前面,而「幼兒心理學」、「犯罪心理學」等專門的書雖然也會被找出,但是會排列在後面(只比對到三個字)。Csmart 根據中文的特性,用比剛才舉的例子更為精準的方式排列查詢結果 [15],讀者可根據查詢結果的符合程度,來判斷排列在後面的資料是不是還有參考的價值,以節省檢視查詢結果的時間。
讀者甚至可以輸入「有關德川加康的日本史」、「胡適寫的文存」等內有錯字或冗字的字串,只要字詞間透露讀者想找的書目名稱即可。而如果書目資料建立得完整,再加上一些技巧,甚至能進一步允許讀者輸入「倪匡的武俠小說」等合併作者與主題檢索的字串,查詢結果會在倪匡種類眾多的小說中,將其武俠小說書目列在前面。對不諳查詢技巧的使用者而言,此種查詢方式極為便利,想到什麼詞句,就輸入什麼字串,而不用關心應該要用 AND 邏輯,或是 OR 運算。Csmart 已開發出語音輸入的版本,將來使用者甚至能用口語來表達查詢條件。
Csmart 是一支通用的檢索引擎程式,可用於不同的用途。因此,以 Csmart 來檢索書目資料時,需以某種自訂的格式準備好書目資料,再撰寫一支使用者介面程式以呼叫 Csmart,並將結果排版輸出。表四是使用者查詢的介面檔案,表五是我們自訂的書目格式。此書目檔案目前包含的內容雖然很簡單,但卻是單純的文字檔案,非常容易擴充資料內容。檔案中每一筆記錄的資料記載以全形字「@」起始,至下一個全形字「@」之前截止,資料欄之間則用「^」符號隔開。符號「@」是 Csmart 用以分隔記錄的字元,「^」則是我們自訂的欄間符號,可以自由選用。Csmart 對資料檔的要求很有彈性,如果有十萬筆資料,可以全部放在同一個檔案,也可以分割成數個檔案放在同一目錄下,但以分割檔案的方式對提昇檢索速度幫助較大。
在 WWW 的架構下,使用者的輸入介面與查詢結果的版面安排可用 HTML 完成。我們選擇 Perl 語言來撰寫輸入的處理、Csmart 的叫用及輸出的控制。因為在各種重要的作業系統上都有 Perl 解譯器 [6],更換作業系統時,只需更換對應的 Perl 解譯器即可。
由 Csmart 查得資料作輸出時,每筆資料必須加上超連結,以便利使用者查得該筆資料的詳細書目。這點與前一節描述的處理類似,亦即,將記錄編號或書名以超連結包含如下:
<A HREF="http://IP_Address/SCRIPTS/LIB.EXE?TEMPLATE=/DETAIL.DBM&BAR=#BAR# &Loc=L">#COUNT_REC#</A>
注意其中的主機位址必須指向存放詳細書目資料的主機。
本文提出以 WWW 為介面的分散式 OPAC 系統架構,並以輔仁大學的書目資料庫為基礎,發展出實際可運作的系統。開發上述的系統,除了安裝必要的軟硬體、準備好書目資料外,我們只需撰寫二個 HTML 使用者介面檔案以及三支小程式就完成了。分散式處理的架構可以充分運用圖書館既有的電腦硬體與網路上免費或低廉的軟體,在連線頻繁、查詢負擔加重後,也容易做到個別模組的升級。此外,由於使用者可用近似自然語言的方式查詢,使得系統不僅因為建構在 WWW 上而容易操作,也讓使用者查詢起來更為直覺便利。WWW 的技術不僅讓圖書館的服務超越時、空的限制,更可貴的是,它是一種開放架構,以及成本低廉的技術。
在 WWW 架構下,個人電腦等級與主機型系統之間的界線越來越模糊,過去對圖書館自動化系統的各項功能要求,均可提出來重新一一檢視,化繁為簡,將效益高、成本低、時程短的項目列為優先完成項目。再配合開放性的架構,模組化的設計,使各模組可在不同的經費與進度的規畫下,彈性的分批開發或採購獲得,並且可以整合在一起,以價廉、物美的系統,提供使用者更便利的服務。
誌謝
本文的完成,感謝中央研究院資訊科學研究所簡立峰博士與李明哲先生提供Csmart軟體與諮詢,並感謝輔仁大學圖書館與資訊中心提供的書目資料、軟硬體設備、以及人力上的支援。
參考資料
[1] "AltaVista Search: Main Page" http://altavista.digital.com/
[2] Andrzej Kowalski, "Re:WEB catalogs that handle MARC records," http://library.wustl.edu/~listmgr/webcat-l/0143.html
[3] Andrzej Kowalski, "Re: Texpress( was Re:WEB catalogs that handle MARC records)," http://library.wustl.edu/~listmgr/webcat-l/0146.html. (註:閱讀此篇時,請以 Microsoft Explore 3.0 瀏覽;若以 Netscape 3.0 瀏覽,請選擇其功能表的「View/Document Source」才能看到全部文件。)
[4 ] 卜小蝶,"Fuzzy Search 技術在中文 OPAC 的應用",中國圖書館學會會報,第56期,85年6月,頁77─86。
[5] WebSEEK: Content-based Image and Video Catalog and Search Tool for the Web http://www.ctr.columbia.edu/webseek/
[6] 曾元顯,"多媒體電子佈告欄",中國圖書館學會會訊,4卷3期(102),8年9月31日。Also available at http://blue.lins.fju.edu.tw/~tseng/papers/ wbs.htm
[7] 「分編問題專欄─分類、編目討論區」,中國圖書館學會, http://blue.lins.fju.edu.tw/lac/catalog/wbs.htm
[8] Allaire Corp. http://www.allaire.com/
[9] 曾元顯,"增加 Home Page 的互動性-- CGI 程式與資料庫的運用",中國圖書館學會會訊,4卷2期(101),85年6月31日。Also available at http://blue.lins.fju.edu.tw/~tseng/cgi.htm
[10] 註:請參考 Innopac 系統的關鍵字查詢功能,如:http://tulips.ntu.edu.tw/search*chi/w
[11] Patrick Hoffman, "Text Information Retrieval on the WEB - with emphasis on search engines, indexing,querying and visualization", http://www.cs.uml.edu/shootout/papers/irsrch.html
[12] Welcome to Lycos, http://www.lycos.com/
[13] GAIS網路資訊搜尋系統簡介,http://gais.cs.ccu.edu.tw/aboutGAIS.html
[14] Csmart:網路中文資源檢索系統,http://csmart.iis.sinica.edu.tw/
[15] Lee-Feng Chien, "Fast and
Quasi-Natural Language Search for Gigabytes of Chinese Texts,"
ACM SIGIR '95, 1995
──────────────────────────────────
<HTML>
<HEAD><TITLE>輔仁大學圖書館書目查詢</TITLE></HEAD>
<BODY><H1>輔仁大學圖書館線上公用目錄</H1>
文圖 : 211472 筆 社圖 : 151224 筆 理圖 : 136133 筆
<HR>
<FORM Method=POST
Action="http://140.136.250.38/scripts/LIB.EXE?template=/CINDEX.DBM"><P>
書 名:<input type=text name="Ti1" size=30>(請輸入書名或書名前幾字)<BR>
作 者:<input type=text name="Au1" size=30>(請輸入姓名,務必輸入姓氏)<BR>
關鍵字:<input type=text name="keyword" size=30>
(請輸入書名中某部分,建議配合作者,書名等條件)<BR><BR>
<input type="submit" value="查 詢">
<HR>
<A HREF="http://140.136.250.38/CHELP.HTM">使用說明</A>
<A HREF="http://140.136.250.40/">回輔仁大學</A>
</FORM></BODY></HTML>
──────────────────────────────────
──────────────────────────────────
<!-- 以 SQL 語法查詢資料庫 -->
<DBQUERY Name="L" DataSource="INDEX" MaxRows=500
SQL=" SELECT * FROM Lindex
WHERE Au1 like '#Form.Au1#%'
AND Ti1 like '#Form.Ti1#%'
AND Ti1 LIKE '%#Form.Keyword#%'
"></DBQUERY>
<!-- 輸出查詢結果 -->
<HTML><HEAD>
<TITLE>Fu-Jen Catholic University Bibliography Search</TITLE></HEAD>
<BODY><H1>查詢結果</H1><HR>
<DBSET #COUNT_REC#=1>
<DBOUTPUT>
您查詢的是 作者:<B>[#AU1#]</B>; 書名:<B>[#Ti1#]</B>; 關鍵字:<B>[#Keyword#]</B>
<BR><BR>
查到 文圖 : <B>#L.RecordCount#</B> 筆
<HR>
<PRE>
筆數 作者 書名 出版年 索書號 館藏
</PRE>
</DBOUTPUT>
<DBOUTPUT Query="L">
<PRE>
<A HREF="/SCRIPTS/LIB.EXE?TEMPLATE=/DETAIL.DBM&BAR=#BAR#&Loc=L">#COUNT_REC#</A>
#AU1# #TI1# #PDT# #NO1#/#NO2# #NO3# #NO4#
<DBSET #COUNT_REC#=#INCREMENTVALUE(COUNT_REC)#>
</pre>
</DBOUTPUT></BODY></HTML>
──────────────────────────────────
──────────────────────────────────
<!-- 以條碼找出該筆書目資料 -->
<DBQUERY Name="ONE" DataSource="L" >
<DBSQL SQL="SELECT ADD, AU1, AU2, AU3, BAR, EDI, HOL, ILL, NO1, NO2, NO3,
NO4, NO5, PCE, PER, PDT, PGE, TI1, TTT, TI3, T3N
FROM Ldb WHERE BAR = '#URL.BAR#' ">
</DBQUERY>
<!-- 輸出查詢結果 -->
<HTML>
<HEAD><TITLE>Fu-Jen Catholic University Bibliography Search</TITLE></HEAD>
<BODY><H1>查詢結果</H1><HR>
<DBOUTPUT Query="ONE" >
<A>索書號 ; 館藏地 : #NO1#/#NO2# #NO3# #NO4# ; #HOL#</A><BR>
<A>書名: #TI1#</A><BR>
<A>作者: #AU1#</A><BR>
<A>合著: #AU2# #AU3#</A><BR>
<A>出版者: #PER#</A><BR>
<A>出版地: #PCE#</A><BR>
<A>出版年: #PDT#</A><BR>
<A>稽核項: #EDI# ; #PGE# ; #ILL# ; #ADD# ; #TTT#</A><BR>
<A>叢書: #TI3# #T3N#</A><BR>
</DBOUTPUT>
</BODY>
</HTML>
──────────────────────────────────
──────────────────────────────────
<HTML> <HEAD><TITLE>輔仁大學書目資料自然語言檢索</TITLE></HEAD <body>
<center>
<H1>輔仁大學書目資料自然語言檢索</H1>
[ <a href="/~reader/wbs/index.htm">讀者討論區</a> |
<a href="http://140.136.250.38/">回主畫面</a> ]<p>
</center>
<HR>
<Form METHOD=get ACTION="/cgi-bin/lib.exe">
查詢字串 :<INPUT size=50 NAME="QueryString">
<DL> 查詢方式 :
<DT><INPUT type="radio" NAME="QueryCommand" VALUE="fuzzy" checked>
自然語言</DT> <DD>(可輸入任意聯想到的字詞,如:
「吳大猷寫的物理學概論導論原理」)</DD>
<DT><INPUT type="radio" NAME="QueryCommand" VALUE="exact">
精確查詢</DT> <DD>(輸入精確字串,常用於查詢人名、地名)</DD>
</DL>
查詢範圍:
<input TYPE='radio' name='LOC' value='1' checked>文圖
<input TYPE='radio' name='LOC' value='2'>社圖
<input TYPE='radio' name='LOC' value='3'>理圖
<input TYPE='radio' name='LOC' value='0'>三館一起查
<br>
文圖 : 211472 筆 社圖 : 151224 筆 理圖 : 136133 筆 <p>
顯示筆數:
<INPUT type=hidden name="rec_from" value=1>
<select NAME="rec_to">
<option>40 <option selected>60 <option>80 <option>100
</select>
<INPUT TYPE="submit" VALUE="開始查詢"><br>
</FORM><HR><center>
本系統檢索引擎為 中央研究院 資訊科學研究所
<a href="http://www.iis.sinica.edu.tw/CKIP/"> Csmart(尋易)系統</a><br>
本系統 WWW 介面發展於12月7日,1996年
</center></body></HTML>
──────────────────────────────────
──────────────────────────────────
@ ^ 史奈德 ^ 天哪!老師不喜歡我 ^ 1995. ^ E047063N ^ 375 ^ 5042 ^ v.2 ^
@ ^ 張景中 ^ 數學家的眼光 ^ 民84[1995] ^ E047102N ^ 510 ^ 1165 ^ ^
@ ^ 張輝明 ^ 展示設計實例 ^ 1994. ^ E047161N ^ 696.5 ^ 1196-2 ^ ^
@ ^ 中谷彰宏 ^ 產生戀愛奇蹟的方法 ^ 民85[1996] ^ E047334N ^ ^ 5803 ^ ^
@ ^ 鍾肇鵬 ^ 讖緯論略 ^ 1994. ^ E047241N ^ 090 ^ 8237 ^ ^
@ ^ 張岱年 ^ 國學今論 ^ 1994. ^ E047240N ^ 079 ^ 1128 ^ ^
──────────────────────────────────