網際網路發展之初提供的服務主要有遠程登錄 (telnet)、電子郵件(email )、檔案傳輸 (ftp),其使用者層面較窄,以美國軍方及具備較高專業知識的大學學生為主。雖然 email 具有商業應用的價值,但其時網路的建置還相當昂貴,網際網路還未普及到民間與一般的商業公司。
近年來硬體與軟體的日益進展,使個人電腦的計算與通訊能力越來越強,再加上大量的免費使用或試用軟體,以及網路上越來越多的資訊系統,如 News、Gopher、BBS、WWW 等,使得網際網路的普及到了水到渠成的地步。國內目前約有五十萬人的使用者,隨者政府的重視與民間的投資,未來兩三年將推廣至三百萬的使用人口。
在這一波網路服務的建設中,各地圖書館也在加緊自動化與網路化的腳步。其中,跟讀者最直接相關的為「線上公用目錄」(OPAC,
Online Public Access Catalog)服務。本期介紹輔仁大學以
WWW(World Wide Web)
為介面,建置的圖書館線上公用目錄系統。
貳、Telnet vs WWW
在 WWW 還未出現以前,圖書館的線上公用目錄主要以遠端登錄
(telnet)的方式,提供網路使用者時空無礙的查詢檢索。Telnet
的優點在於整個查詢的過程中系統一直維持與使用者的連線、並維護使用者查詢的狀態,使得查詢結果的修飾,如縮小範圍、不同查詢結果的聯集運算等,可以直覺的進行。然而
WWW 出現後,卻相對的暴露出以 telnet
為使用者介面的許多缺點。茲列舉如下:
一、只有文字模式,缺乏展現多媒體的能力。而且受限於文字模式顯現字數的限制,顯現的資料常有截斷或濃縮的現象。
二、以終端機模擬方式提供使用介面,游標的移動、文字的輸入、畫面的轉換,均需傳送回遠方主機才能更新畫面,在網路擁塞時,系統回應速度緩慢,並且不能利用已經傳送過的資料加快畫面的顯示。此外,查得的資料需逐頁的顯示,不利於大幅度的翻頁檢視。
三、不同的系統,採用不同的指令與操作方式,對使用者造成困擾。
四、使用者上線人數受限,擴充使用者人數的權利金高昂。一般 Unix 主機,同一時段中接受 telnet 方式簽入(login)系統的人數有限,此人數上限與 CPU 速度、主記憶體容量及使用的軟體有關。Telnet 簽入乃專線獨佔,具有排他性,即簽入一名,後續連線的人數便減少一名。若使用者簽入後不做任何事或不熟悉系統的操作,將造成系統使用效率的低落。
五、查詢檢索程式在
telnet 的架構下,不具備跨平台的特性,軟體移植性差。目前只有
Unix 等大型系統提供
telnet 連線方式,Windows
NT 等系統還未提供,使得軟、硬體的建置費用與維護成本高昂,無法利用較為普及與平價的硬體平台與軟體。
WWW 技術出現後,恰可改進上述缺點。WWW
作為使用者介面的優點有
一、介面一致、簡單易用
WWW 圖形化的介面、超連結的功能,使用者只需根據畫面上的圖示或簡短說明,利用滑鼠的點選操作即可,免除查閱並記憶指令的過程。目前網路技術的發展,有傾向於使用者只要學會瀏覽器的使用,即可享受各種網路服務的趨勢。
二、充分運用使用者端的電腦資源
使用者移動游標、輸入資料或畫面轉換時,只由使用者端的電腦處理,不必等待主機端的回應。而且大部份的瀏覽器會將傳送過的資料做備份,使再次抓取或顯示的速度加快,降低網路的負荷量。此外查詢的資料若經傳送完畢,使用者就可以快速翻閱檢視,不受網路速度的影響。若查得的資料數量很大時,逐筆的瀏覽檢視還是相當吃力。這種情況,可利用瀏覽器的字串搜尋功能,做快速跳躍,加快資料的瀏覽篩選。
三、無使用者上線人數的限制
WWW 以 HTTP(HyperText Transfer Protocol)的通信協定連線,此協定的特點是每次傳送資料就要重新建立連線,資料傳送完畢後,就斷線。這使得使用者下完查詢條件,要求檢索資料時,才需要連上主機,伺服器端一旦查到資料並傳送完畢後,隨即斷線,等待下一位使用者的查詢。一般 WWW 伺服器可接受多個使用者同時的查詢,但畢竟還是有限,可是若查詢與傳回資料的速度夠快,很快就可以服務完一個查詢,對使用者而言則幾乎沒有上線人數的限制。網路上的 Alta Vista 檢索引擎一星期可服務兩千萬人次,即為例證 [1]。
四、開發簡易、不與既有系統衝突
以 telnet 為介面的查詢檢索程式在資料庫管理系統的支援下,查詢存取資料並不困難,反而要在文字模式下與使用者做友善、直覺的互動需花一番工夫處理。現在透過 WWW 的架構,使用者介面可以用 HTML 語法完成,如有必要則輔以 Java或 ActiveX 程式的互動效果,而查詢程式則在伺服器端透過 CGI(Common Gateway Interface)介面及資料庫介面處理資料庫的存取、查詢與輸出結果的版面安排即可。這種架構使得系統具備更高的模組化,變更模組或加強模組功能不會影響到其他部份。因此,如台大、清大等原來就有OPAC 系統(telnet 版本)的大學,很快就有了 WWW 介面的系統。類似的系統,如果能夠自行開發,應該可以節省高昂的使用授權費。
五、超連結、分散式處理、降低對大型主機的依賴
一般的查詢模式都以兩個階段來顯示資料,第一階段顯示每一筆記錄的簡略資料,待使用者選定某一筆記錄後,在第二階段再顯示該比記錄的詳細資料。此兩階段可視為二次的查詢,第一次查詢的範圍較廣,第二次則指定查出某筆記錄。透過 WWW 的超連結能力,此兩階段查詢可以分散在不同的主機處理,減輕查詢主機的負擔。甚至,第一階段的查詢可以在另一部主機利用較先進的演算法,提供使用者更簡易的介面,例如以近似自然語言的方式來表達查詢主題 [2]。資料放在不同主機需要特別注意資料一致性的問題。所幸作為第一階段查詢用的書目記錄,不牽涉到需要及時更新的資料,如讀者預約記錄,此簡略書目不需要以每分鐘或每小時的速率更新,每天或每週的某幾天更新即可。在此情況下要維護資料的一致性較無問題,僅需在使用量最低時,如深夜或清晨,以程式自動更新即可。
六、多媒體、擴充能力佳
WWW 的架構不僅可以讓 OPAC 或類似的系統用來查詢書目記錄,也可以查詢影像、錄音帶、錄影帶、書法或繪畫等資料,並能播放一小段。目前此種系統雖然不普及,但已有一些已在網路上可以看到 [3]。
七、易與其他資訊系統結合
目前 WWW 上的資訊服務系統越來越多,例如中國圖書館學會在網路上就有一個「分類編目討論區」
[4][5],提供各地館員有關圖書分類與編目的參考服務。像這樣的系統也可以用來作為對讀者的參考服務或常問問答集(FAQ,
Frequently Asked Questions)使用,提昇網路化服務的品質。而與此類系統相連,只要建立一個超連結即可。
參、 WWW 介面的 OPAC 系統
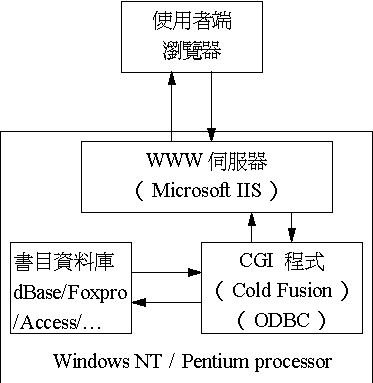
輔仁大學目前的 OPAC 架構如圖一所示。硬體方面以 Pentium 等級的個人電腦為平台。作業系統為 Windows NT 3.51 中文版,WWW 伺服器為微軟公司的 IIS(Internet Information Server)。我們採用 Cold Fusion 這套軟體作為 WWW 伺服器與資料庫之間的介面程式。Cold Fusion 是先試用,後付費的軟體,可以在網路上取得 [6]。它的運作方式與 mSQL 的 w3-msql [7] 基本概念相同,不過它將「HTML中內嵌查詢語言」的概念進一步發展成「資料庫標示語言」(DBML, DataBase Markup Language)的概念,使設計者更方便撰寫有關資料庫的 WWW 應用系統。Cold Fusion 能抓取 WWW 伺服器送來的查詢資料,並允許設計者用SQL查詢語法(Structured Query Language)表達查詢條件,透過資料庫軟體所附的 ODBC (Open DataBase Connect)介面,可以存取、查詢 dBase、Foxpro、Access、MS SQL 等多種資料庫的資料。查詢結果,則以 DBML 與 HTML來安排版面。Cold Fusion 此種彈性的架構,使得我們將原先為 dBase 格式的資料庫檔轉成 Foxpro 的資料庫檔時,只需選用對應的 ODBC 介面,而完全不必更動到系統的其餘部份。
輔大 OPAC 的使用者查詢介面可以連到 http://140.136.250.38/cindex.htm
上看到。表一是使用者查詢畫面的 HTML 檔案。注意其中的一行:
Action="http://140.136.250.38/scripts/LIB.exe?template=/CINDEX.DBM"
其中「LIB.exe」是 Cold Fusion 的主程式,「template=/CINDEX.DBM」是其參數,指示 Cold Fusion 以 CINDEX.DBM 為模版,來處理此查詢。簡略過的CINDEX.DBM 檔案列在表二。Cold Fusion 根據此 "程式",從簡略的書目資料庫 "Lindex" 中查出符合條件的記錄,存放於變數 "L" 下,接下來則輸出這些記錄的「筆數」、「作者」、「書名」、「出版年」、「索書號」、「館藏」等資料。此乃第一階段的查詢。至於第二階段的查詢,使用者只要在「筆數」上用滑鼠點一下,即可查到該比記錄的詳細書目資料。這是透過下面這行敘述做到的:
<A HREF="/SCRIPTS/LIB.EXE?TEMPLATE=/DETAIL.DBM&BAR=#BAR#&Loc=L">#COUNT_REC#</A>
同樣的,「LIB.EXE」是 Cold Fusion 的主程式,「template=/DETAIL.DBM& BAR=#BAR#&Loc=L」是其參數,指示 Cold Fusion 以 DETAIL.DBM 為模版,帶入「BAR="條碼號碼"」以及「Loc=L」作為參數,來處理此查詢。DETAIL.DBM 的大致內容列在表三。Cold Fusion 根據此 "程式",從詳細的書目資料庫 "Ldb" 中查出符合所給條碼號碼的記錄,存放於變數 "ONE" 下,接下來則輸出這筆記錄的詳細書目資料。
此種架構有前一節所描述的優點,使我們發展此系統時有極大的彈性與便利,並在二、三週內完成基本的功能。未來若要以另一部主機,提供較佳的查詢方式,例如容許使用者記錯字或以近似自然語言方式表達查詢條件,則只需安裝該查詢主機,並修改下面兩個地方即可。一是 「CINDEX.HTM」 裡的
Action="http://140.136.250.38/scripts/LIB.exe?template=/CINDEX.DBM"
將其中的主機位址改成新安裝的查詢主機位址。二是「CINDEX.DBM」裡的
<A HREF="/SCRIPTS/LIB.EXE?TEMPLATE=/DETAIL.DBM&BAR=#BAR#&Loc=L">#COUNT_REC#</A>
將其中的 URL 位址改成:
<A HREF="http://140.136.250.38/SCRIPTS/LIB.EXE?TEMPLATE=/DETAIL.DBM&BAR=#BAR# &Loc=L">#COUNT_REC#</A>
即可。
圖書館自動化系統一般分為「線上公用目錄」、「流通」、「期刊控制」、「編目」及「採購」五大模組。本文僅觸及到「線上公用目錄」模組,以此推論其他模組也可以用類似的架構完成,理論上是合理的推演。當我們檢視 PC 等級的自動化管理系統時,發現其所採用的技術相當單純,可是要處理繁多的細目、協定,卻要投入相當多的時間。因此,實際上發展時會面臨預算、時程、軟體工具的成熟度、人力的配合以及各單位的協調與共識等問題的挑戰。
在 WWW 架構下,個人電腦等級與主機型系統之間的界線越來越模糊,過去對圖書館自動化系統的各項功能要求,均可提出來重新一一檢視,化繁為簡,將效益高、成本低、時程短的項目列為優先完成項目。再配合開放性的架構,模組化的設計,使各模組可在不同的經費與進度的規畫下,彈性的分批開發或採購獲得,並且可以整合在一起,以價廉、物美的系統,提供使用者更便利的服務。
誌謝
本文的完成,感謝輔仁大學圖書館與資訊中心提供的書目資料、軟硬體設備、以及人力方面的支援。
[1] "AltaVista Search: Main Page" http://altavista.digital.com/
[2] 卜小蝶,"Fuzzy Search 技術在中文 OPAC 的應用",中國圖書館學會會報,第56期,85年6月,頁77─86。
[3] WebSEEK: Content-based Image and Video Catalog and Search Tool for the Web http://www.ctr.columbia.edu/webseek/
[4] 曾元顯,"多媒體電子佈告欄",中國圖書館學會會訊,4卷3期(102),8年9月31日。Also available at http://blue.lins.fju.edu.tw/~tseng/papers/wbs.htm
[5] 「分編問題專欄─分類、編目討論區」,中國圖書館學會, http://blue.lins.fju.edu.tw/lac/catalog/wbs.htm
[6] Allaire Corp. http://www.allaire.com/
[7] 曾元顯,"增加
Home Page 的互動性-- CGI 程式與資料庫的運用",中國圖書館學會會訊,4卷2期(101),85年6月31日。Also
available at http://blue.lins.fju.edu.tw/~tseng/cgi.htm
<HTML>
<HEAD><TITLE>輔仁大學圖書館書目查詢</TITLE></HEAD>
<BODY>
<H1>輔仁大學圖書館線上公用目錄</H1>
文圖 : 211472 筆 社圖 : 151224 筆 理圖 : 136133 筆
<HR>
<FORM Method=POST
Action="http://140.136.250.38/scripts/LIB.exe?template=/CINDEX.DBM">
<P>
書 名:<input type=text name="Ti1" size=30>(請輸入書名或書名前幾字)<BR>
作 者:<input type=text name="Au1" size=30>(請輸入姓名,務必輸入姓氏)<BR>
關鍵字:<input type=text name="keyword" size=30>
(請輸入書名中某部分,建議配合作者,書名等條件)<BR><BR>
<input type="submit" value="查 詢">
<HR>
<A HREF="http://140.136.250.38/CHELP.HTM">使用說明</A>
<A HREF="http://140.136.250.40/">回輔仁大學</A>
</FORM>
</BODY>
</HTML>
<!-- 以 SQL 語法查詢資料庫 -->
<DBQUERY Name="L" DataSource="INDEX" MaxRows=500
SQL=" SELECT * FROM Lindex
WHERE Au1 like '#Form.Au1#%'
AND Ti1 like '#Form.Ti1#%'
AND Ti1 LIKE '%#Form.Keyword#%'
"></DBQUERY>
<!-- 輸出查詢結果 -->
<HTML><HEAD>
<TITLE>Fu-Jen Catholic University Bibliography Search</TITLE></HEAD>
<BODY><H1>查詢結果</H1><HR>
<DBSET #COUNT_REC#=1>
<DBOUTPUT>
您查詢的是 作者:<B>[#AU1#]</B>; 書名:<B>[#Ti1#]</B>; 關鍵字:<B>[#Keyword#]</B>
<BR><BR>
查到 文圖 : <B>#L.RecordCount#</B> 筆
<HR>
<PRE>
筆數 作者 書名 出版年 索書號 館藏
</PRE>
</DBOUTPUT>
<DBOUTPUT Query="L">
<PRE>
<A HREF="/SCRIPTS/LIB.EXE?TEMPLATE=/DETAIL.DBM&BAR=#BAR#&Loc=L">#COUNT_REC#</A>
#AU1# #TI1# #PDT# #NO1#/#NO2# #NO3# #NO4#
<DBSET #COUNT_REC#=#INCREMENTVALUE(COUNT_REC)#>
</pre>
</DBOUTPUT>
</BODY></HTML>
<!-- 以條碼找出該筆書目資料 -->
<DBQUERY Name="ONE" DataSource="L" >
<DBSQL SQL="SELECT ADD, AU1, AU2, AU3, BAR, EDI, HOL, ILL, NO1, NO2, NO3,
NO4, NO5, PCE, PER, PDT, PGE, TI1, TTT, TI3, T3N
FROM Ldb WHERE BAR = '#URL.BAR#' ">
</DBQUERY>
<!-- 輸出查詢結果 -->
<HTML>
<HEAD><TITLE>Fu-Jen Catholic University Bibliography Search</TITLE></HEAD>
<BODY><H1>查詢結果</H1><HR>
<DBOUTPUT Query="ONE" >
<A>索書號 ; 館藏地 : #NO1#/#NO2# #NO3# #NO4# ; #HOL#</A><BR>
<A>書名: #TI1#</A><BR>
<A>作者: #AU1#</A><BR>
<A>合著: #AU2# #AU3#</A><BR>
<A>出版者: #PER#</A><BR>
<A>出版地: #PCE#</A><BR>
<A>出版年: #PDT#</A><BR>
<A>稽核項: #EDI# ; #PGE# ; #ILL# ; #ADD# ; #TTT#</A><BR>
<A>叢書: #TI3# #T3N#</A><BR>
</DBOUTPUT>
</BODY>
</HTML>